The TL;DR? We used OFRAK to rewrite the badge firmware so that it auto-plays the solution for Challenge 1.
Est. read time: 20 min read
The code referenced in this writeup can be found here.
DEF CON 30 just ended, and the badge this year was awesome. It included a playable synthesizer with a few instrument presets, as well as buttons, a screen, and a small speaker. Everything on the badge was driven by a Raspberry Pi Pico. As usual, the badge also had an associated reverse engineering challenge.
Several of us from Red Balloon Security attended and manned booths in the Aerospace Village and Car Hacking Village. Many of our demos were based on OFRAK, which we released publicly at DEF CON 30. Since OFRAK is a binary reverse engineering and modification platform, it naturally became our tool of choice for badge firmware modification.
This post walks through using OFRAK to modify the DEF CON 30 Badge firmware in fun and exciting ways. We are unabashedly building off of this great write-up. @reteps, we owe you a beer! (Or a ginger ale, since it seems like you may not be old enough to drink just yet.)
This write-up is long, so feel free to skip ahead to the parts that interest you:
Set up OFRAK
To walk through this writeup with us, you will need to install picotool and ofrak. Run these steps in the background while you read the rest of this document.
We use picotoolto export the firmware image.
You can now use picotool to export the firmware image from the device. To do this, the badge must be in BOOTSEL. To put the badge in BOOTSEL, hold down the badge’s down button while powering the device, or short the J1 pins on the back with a jumper wire. You can now connect the device to your computer over micro USB.
If you have done this correctly, running picotool should give the following output:
You can now dump the badge firmware as a raw binary file, badge_fw.bin, using the following command:
Insert logo with OFRAK GUI
First things first – let’s replace the DEF CON logo that appears when the badge is powered on with an OFRAK logo!
1. Load the image into the OFRAK GUI.
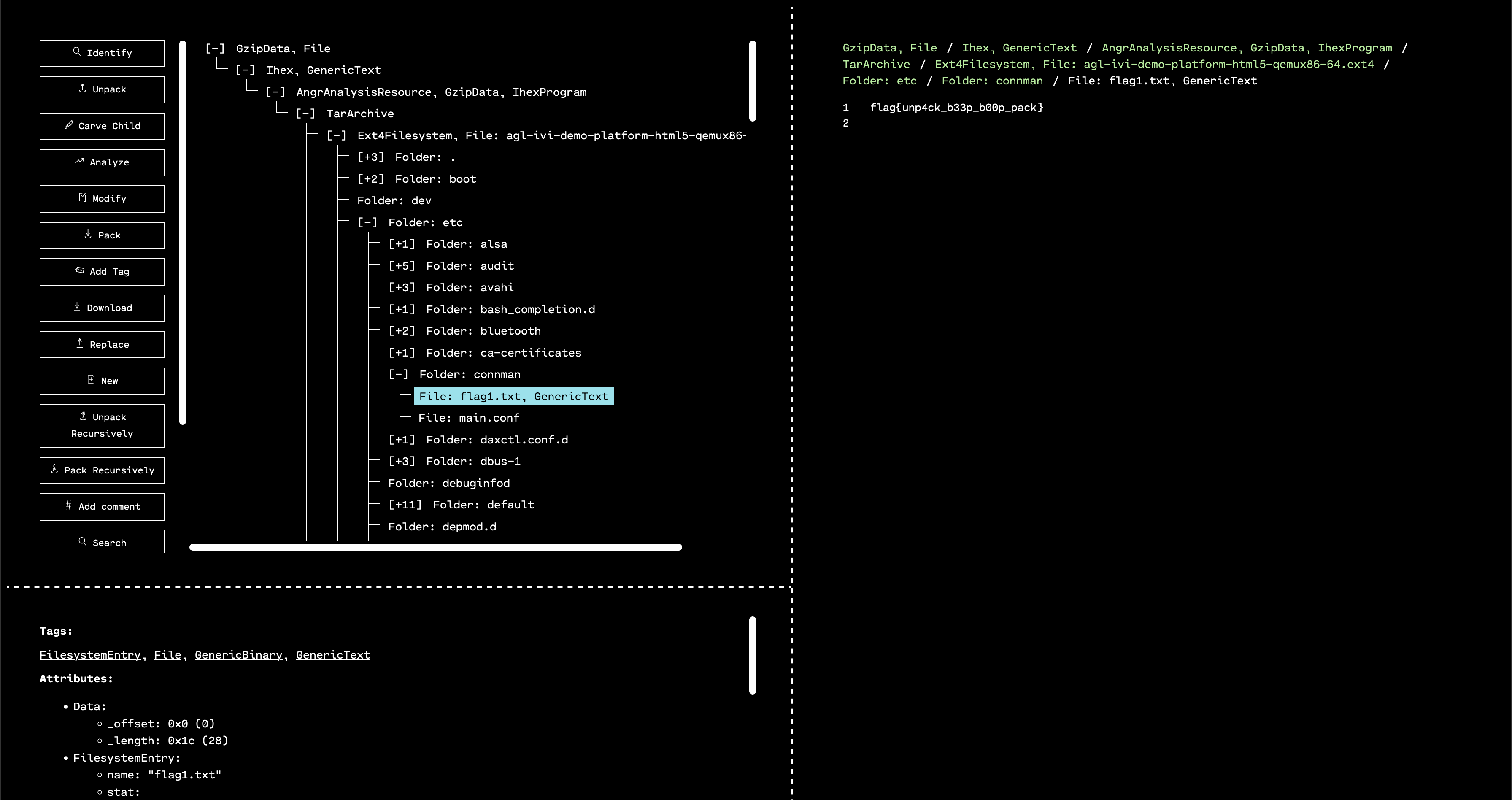
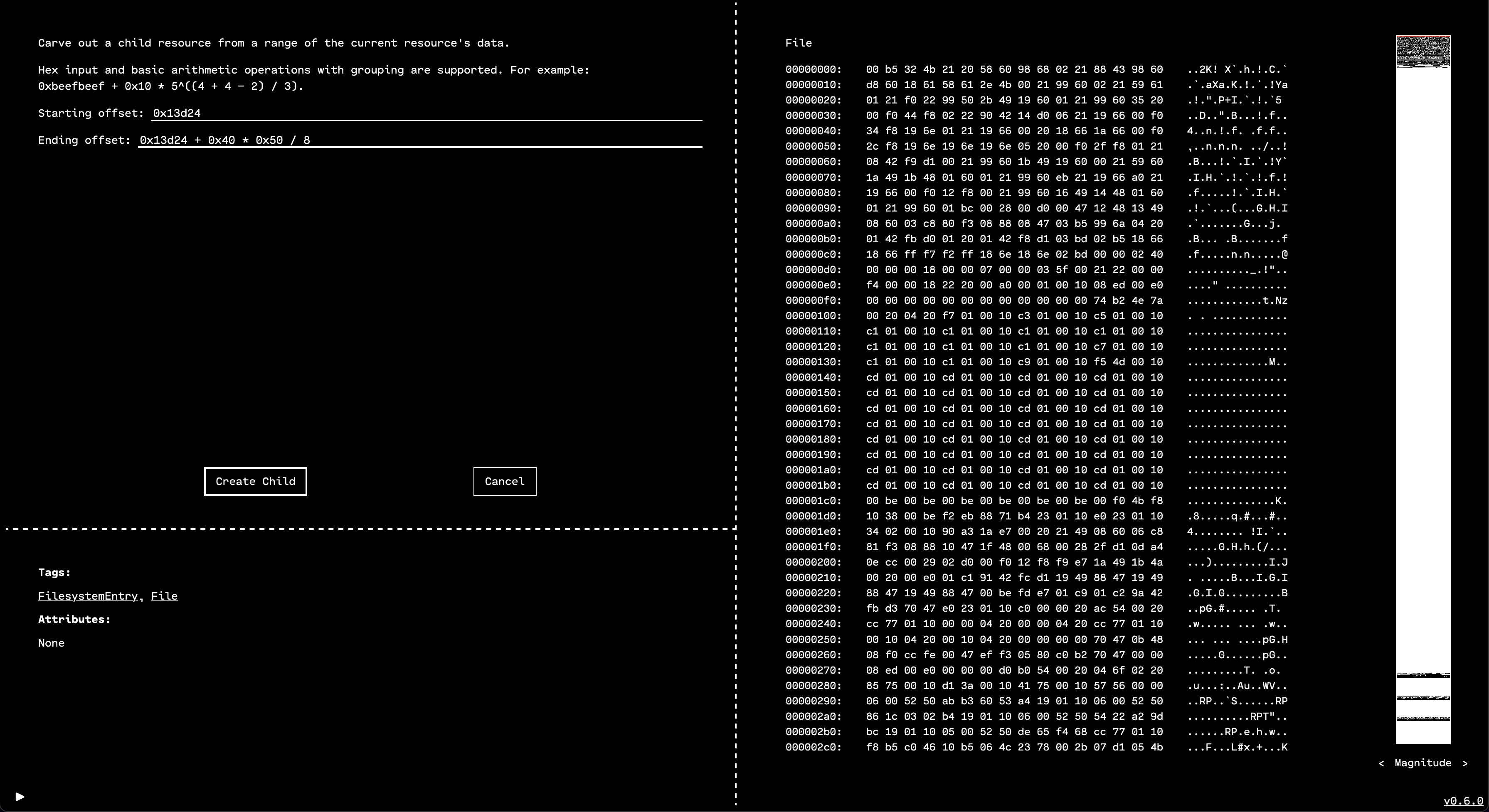
2. We know from the reteps writeup that the DEF CON logo is at offset 0x13d24, so we can use the “Carve Child” feature in the OFRAK GUI to unpack it as a separate resource.
Carve from offset 0x13d24 with a size of 80 by 64 pixels, each of which is stored in a single bit (so divide by 8 to get the number of bytes).
Looks good!
4. Download this pre-built OFRAK Logo from here, or expand more information about building a custom image below.
5. Use the OFRAK GUI “Replace” feature to replace the data.
6. Pack the whole thing back up.
7. Download the resulting firmware image and flash it onto the device.
8. Verify that it works by booting up the badge.
Looks good!
We can now automate this step in future firmware mods by using the following Python function:
Change some strings
It is easy to use OFRAK to change strings within the badge firmware. The function ofrak_the_strings (listed below) changes the “Play” button on the badge’s menu to display “OFRAK!” and hijacks the credits, giving credit to OFRAK mascots (“mushroom”, “caterpillar”) and “rbs.”
Press any key to win Challenge 1
OK, now on to Challenge 1! For those of you who didn’t participate in BadgeCon: You win Challenge 1 on the DEF CON Badge if you play the melody to Edward Grieg’s Peer Gynt.
Peer Gynt is nice, but some of us can’t play the piano (or are too lazy). We want to win Challenge 1 without any musical skills/effort.
The reteps writeup points us to a two-byte binary patch that does just that. The ofrak_challenge_one function below patches the badge firmware such that pressing any key wins Challenge 1!
Autoplay Notes (Piano Player) to win Challenge 1
Jumping right to the win condition is fun and all, but isn’t half the fun of the badge that it makes sounds? What if we could just have it… make sounds? Sounds that happen to make us win?
The goal of this section is to use OFRAK to patch the badge firmware into “Player Piano” mode: When you start Challenge 1, the badge autoplays Peer Gynt for you and you win. This is not too complicated, but it requires us to put on our Reverse Engineer hats and dig deeper into the firmware.
Step 1: Reverse Engineering
The first step was to pull the firmware and throw it into Ghidra. Luckily, we didn’t have to start from scratch.
Step 0: Plagiarize Survey the Literature
Shoutout (again) to the reteps writeup, which was a great starting point. If he shared his Ghidra project, we didn’t see it, but in his writeup we could see one important function labeled and with a full address! What he called z_add_new_note_and_check at 0x10002df0, we called check_challenge, but it does the same thing either way. That was essentially our starting point, from which all other analysis stemmed.
Step 1v2: Reverse Engineering
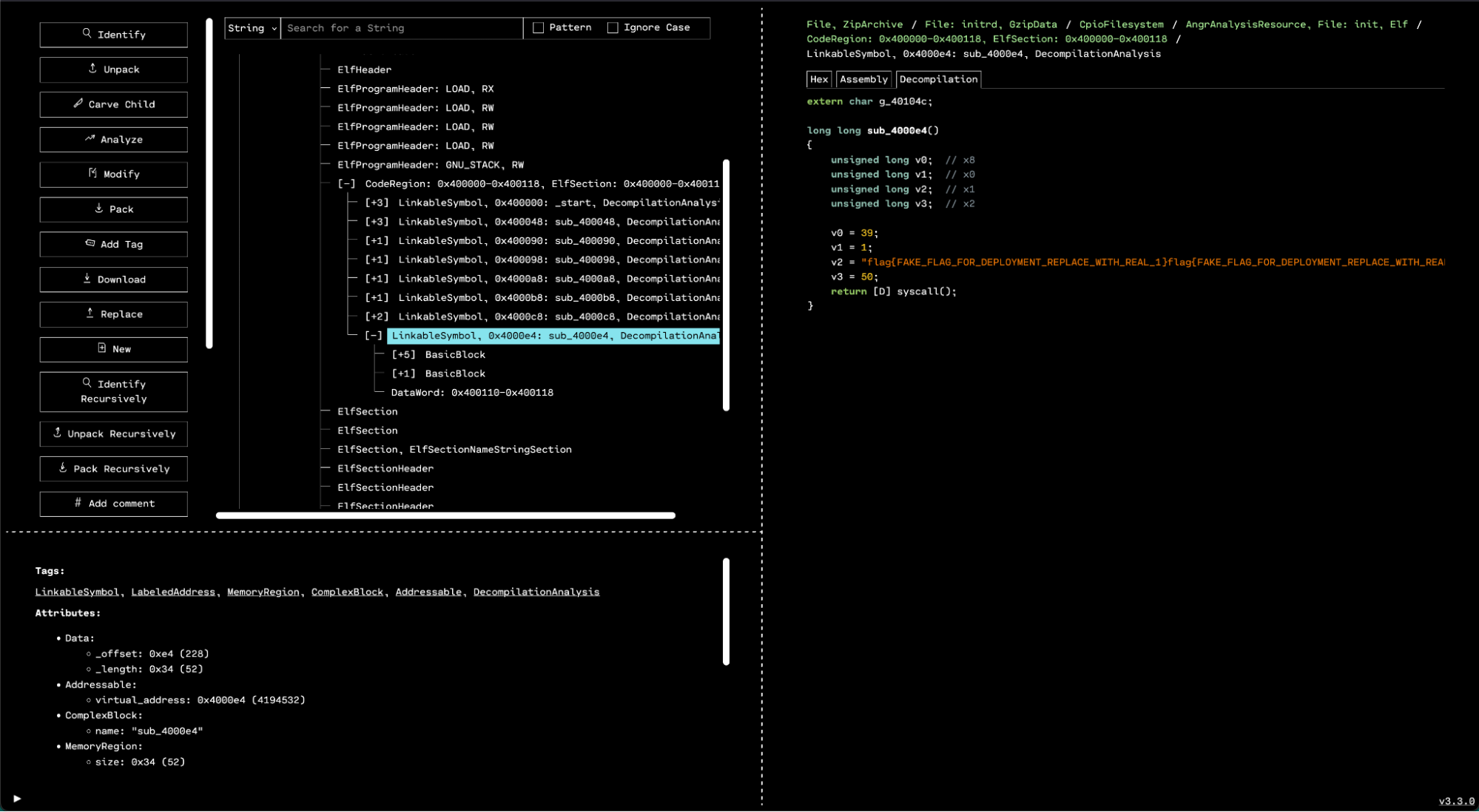
Our first approach was looking at code xrefs to check_challenge since A) that was our foothold and we did not have any other good starting points, and B) the latest note played was passed to this function, so it seemed to make sense to trace that data flow and find out how the latest note played is read. Then, in theory, we could write a new note there programmatically. The immediate problem was that most usages of check_challenge were in a function we affectionately called big_chungus because it was large and hard to understand. The decompilation looked like this:
Which was essentially unusable except in very local instances.
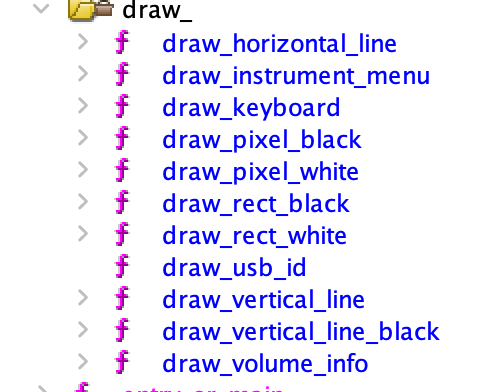
The next approach we took was looking at strings. We quickly found some interesting strings we had seen on the screen, so we followed those references and found a number of functions related to drawing pixels (below screenshot shows them after they were labeled):
This led to the functions that drew each of the menus, which gave us a good idea of the state machine that the firmware uses. Throughout the process, we used OFRAK to experiment with different hypotheses by injecting bits of assembly to poke at addresses. For example:
This helped us to confirm or reject these hypotheses. It was also just fun to change the behavior. We used this function to change all of the keys’ associated light colors to green, since the code for that is all in a big regularly-patterned block and we could iterate over it at constant offsets:
After mucking around for a while, we were not completely sure we had found the “source” of the notes. We had some ideas, though they would require more complex experiments, which would be cumbersome to write in assembly. At this point, we decided to set up the OFRAK PatchMaker for the badge firmware.
Step 2: PatchMaker
The PatchMaker is a Python package for building code patch blobs from source and injecting them into an executable OFRAK resource. In this case, we wanted to be able to “mod” the badge firmware by just writing out some C code with full access to the existing functions and data already in the device.
The first step is to set up the toolchain configuration:
This is pretty standard stuff for C-patching an existing firmware. We decided to use the PatchFromSourceModifier to do that actual patching, as it hides some of the nitty-gritty of building a patch (though it consequently has fewer options than going through the core PatchMaker API).
The next step is to define the symbols that can be used from the patch source code. These need to be exposed to PatchMaker by adding some LinkableSymbol data structure to the existing Program:
And they need to be exposed to the C code by declarations, as one might normally see in a header:
Then we could write some C code referencing those; no spoilers though, we’ll show that code later! To actually build it, we create an empty root resource to hold the source code and run PatchFromSourceModifier:
The source bundle resource ID, the TOOLCHAIN_CONFIG, and TOOLCHAIN_VERSION were already explained but what about the Segments?
Step 3: Free Space & Segments
In order to inject code, we obviously need a location to inject it into. There are three options for how to obtain this:
- Find some unused space in the binary.
- Enlarge/extend the firmware binary so more bytes are loaded into memory.
- Replace something that already exists in the binary.
These are roughly ordered from “best” to “worst.” Ideally we want to change as little possible in the binary. In this situation though, we were limited to the third option:
- We did not have complete knowledge of the binary and could not say with 100% confidence that some part was unused (this is usually the case).
- We did not yet have an OFRAK packer/unpacker for uf2, the file format the binary was in.
So the next task was to choose something to overwrite. We found the function that drew the little volume slider on the side, and this seemed a good choice because:
- It would free up a decent amount of space (over 256 bytes to drop THUMB code in).
- It was called often and consistently (alongside other screen-updating code).
- Removing it would give us some real estate on the right edge of the screen to write/draw new stuff to!
We verified that this would have no ill effects by gutting the contents of the function with nop instructions:
If we are just patching in some compiled C patch over the existing code, NOPing it out first isn’t strictly necessary, but it is a good sanity check that removing the function is probably fine. It also verifies the function does what we think it does: The volume slider is gone!
With our target address picked out, we defined the PatchMaker Segments where our compiled code and data would be inserted:
The first is for the code, and the second is a healthy allocation for read-only data, like constants and strings.
At this point we were ready to start writing some C.
Step 4: The Payload
We wrote a number of experiments in C code, experimenting with various memory addresses and functions we were investigating. C is brilliant because it is so much nicer to work in than assembly, but just as unsafe. One trick we used liberally was the ability to cast memory locations to whatever pointer type we wanted: this allowed us to quickly iterate and peek/poke addresses that we thought contained interesting data Here are some snippets from our experiments:
This writes out the index of the currently selected instrument, and below that draws the two most recently played notes.
The characters drawn (“@”, “<“) representing the notes just happen to be ASCII; they are uint8_t indexes in essentially a long array of all possible notes in all octaves, so 84 values. G# in the lowest octave is the first visible “character”, at 0x20 meaning ” ” (space), below this the draw_character function just draws a white rectangle. Then B in the highest octave is the highest byte, 0x6B (“k”). Here “@” and “<” mean the most recent notes played are E and C in the 4th octave.
Recall that write_character is a function analyzed from the existing binary, and we can call it and link against it like writing normal C code! This is the power of PatchMaker.
At this point we had a good loop: Follow some code and/or data in Ghidra for a while until we think we understand it, then write a C patch to use that knowledge to test our theory. After a little bit, we had found a bitmap at 0x20026eea that seemed to store the info about which keys were currently held; some experiments confirmed this. At this point, we had all the information we needed to write a “Player Piano” for the badge!
Step 5: Forward Engineering
After all the reverse engineering, there were a few “forward” engineering challenges to consider, so we’ll just rapid fire through them:
Timing
We wanted the notes to be audible one after the other, so that meant we had to time them. We didn’t find any timing functions, and probably would not “trust” them even if we did. We decided to just use a counter we would increment each time our function was called (like a C static local variable) and play/increment notes according to that. This meant we needed some R/W space, which we implemented quick & dirty by finding some free scratch space and defining pointers to those as LinkableSymbols.
We got the addresses by going to the memory segment we had defined in Ghidra for in-memory RW data, and finding the address at which we stopped seeing references. Luckily this was 0x20026f04, not near an obvious page-end boundary, so we felt reasonably confident we could read/write to it as much as we wanted. Then we defined the LinkableSymbols for it:
In C we could use those as extern r/w variables:
Storing and writing the sequence
Since the target we needed to write notes to was a bitmap, where each bit is a single note, it made sense to define each note as the bit in the bitmap it was mapped to. This could either be represented as bit index (i.e. 0x3 means “third bit”) or a bit mask (i.e. 0x8 means “third bit” because the third bit is set). In the end we chose bit index because it was more compact, requiring only one byte per note in the 12 notes (plus 3 samples).
Then, we could store the correct sequence as a constant and iterate over that. The correct sequence could be found in memory (in the octave-offset representation we explained in the earlier Payload section) at address 0x1000dac8 (thanks again to reteps for finding this.) Converted to our C enums:
Starting playing the sequence
Initially, we had the sequence play in a loop forever, as soon as the “Play” menu came up.
This got a bit annoying. We had already figured out a few of the other inputs we could use to trigger the sequence, and settled on all three of the samples being played at once when in a specific instrument. Then switching out of that instrument would stop the sequence. This was much better for our sanity. We also added some initialization code for the counters, just to be sure they would start at 0. We wrote some specific magic value to one of our scratch variables to keep track of whether the state was initialized or not. A saner alternative would have been to find the initialization/startup code and hook into that, but this was a bit easier.
We arbitrarily chose the violin as the autoplay instrument.
Closing Thoughts
This was good, fun and an exercise in using OFRAK “recreationally.” We, of course, are partial to OFRAK, but it was great scripting everything in Python and having access to a library of very helpful binary analysis and patching functionality.
Some future additions that could be done on this badge FW modification:
- Making the autoplayer a separate “instrument” so it shows up on the instrument select screen. It would be a neat trick, but you’d have to stop the badge from thinking it’s an actual instrument and trying to play sounds that don’t exist (there appear to be jump tables for each instrument)
- Making multiple new instruments for different pre-set tracks
- Recording sequences of notes as new pre-set tracks at runtime
- Using the various drawing functions to draw pictures according to the notes played, like a music visualizer
All of these would require rather significant additional space, so we would need a way to extend the firmware for sure. Sit tight for an OFRAK Modifier for that!
Some sticking points with OFRAK we noticed that got us thinking:
- It bothered us (aesthetically and practically) that we were defining functions and data in two places: The “extern” declarations in source/header, and the
LinkableSymbol that actually defined the value. It seems practical and more convenient to define functions along with their type in one place, perhaps just pulling these straight from Ghidra, and have OFRAK creating the declaration and definition without any more user input needed. - Managing data sections (both R and RW) through the
PatchFromSourceModifier API is a bit impractical. This can always be tricky with PatchMaker, but the Modifier’s API abstracts away the guts that it is unfortunately necessary to bury your hands in to get things working smoothly. For example, we originally tried to used LLVM instead of GNU, but LLVM stubbornly insisted that extern pointers to data had to first be loaded as an indirect pointer from the .rodata section, which pointed to an address in the .bss section, where the address of the variable would hopefully be contained. GNU was happy to just load the variable address directly from the .rodata section. Managing an additional section was more effort than switching toolchains, which is a testament to interoperability and modularity in PatchMaker but a flaw in PatchFromSourceModifier.
Perhaps these will become pull requests you’ll see landing in core OFRAK shortly 
Hope you enjoyed our work! Maybe next you can build something else cool on top of the badge!
— Edward Larson & Jacob Strieb

")

")